GIT en detalle
![]()
GIT es un sistema de control de versiones distribuido, gratuito y de código abierto, diseñado para gestionar desde proyectos pequeños a muy grandes con rapidez y eficacia. No depende de un repositorio central, múltiples usuarios pueden instalarse GIT y comunicarse entre ellos sin pasar por dicho servidor central. Lo que pasa es que sería inmanejable, así que los “servidores o repositorios centrales (remotos)” son muy útiles y necesarios, los más famosos son GitHub, GitLab y Gitea.
Introducción
¿Porqué mola GIT?. Hay muchos motivos, como su velocidad, que lo hizo Linus Torvals, que es libre, que nos permite movernos, como si tuviéramos un puntero en el tiempo, por todas las revisiones de código y desplazarnos de una manera muy ágil.
Tiene un sistema de trabajo con ramas (branches) que lo hace especialmente potente. Permiten poder tener proyectos divergentes de un principal, hacer experimentos o para probar nuevas funcionalidades, entre otras cosas.
Antes de entrar en harina, tenemos dos formas de trabajar, con el cliente (programa) git para la línea de comandos o con un cliente gráfico, muchísimo más sencillo y agradable. Aún así te recomiendo empezar por la línea de comandos (git a secas) y cuando entiendas cuatro cosillas importantes te pases a un cliente GUI.
- Cliente
git, programa para línea de comandos - Cliente GUI GitKraken <- Este es el que uso yo 🤗
- Cliente GUI GitHub Desktop desarrollado por GitHub.
- Cliente GUI SourceTree
- Aquí tienes más.. clientes GUI
- También puedes buscar talleres como este en otros idiomas (aquí un ejemplo)
| Importante: En este apunte voy a usar la nomenclatura git en inglés, evito traducir los palabros, Internet está plagada de ejempos, tutoriales y documentos sobre git y el 99% utilizan su nomenclatura en inglés, así que mejor no liarnos… |
| Inglés | Español | Descripción |
|---|---|---|
| staging area | área de preparación | Es una zona intermedia (dentro de .git) donde se van preparando archivos a la espera del ser usados en el siguiente commit |
| index | índice | Es la lista de todos los archivos que se están preparando a los que hacemos seguimiento y están en la staging área (entre tu working copy y el futuro commit). |
| working copy | directorio de trabajo | Es el directorio completo de tu proyecto, la parte no controlada por git, es decir, todos los ficheros y directorios que están fuera del subdirectorio .git |
| commit | confirmar, comprometer | Consiste en dar por bueno lo que tenemos en el Staging Area y pasarlo a un estado de “confirmado”, identificándolo con un puntero numérico (hash del commit). Junto con sus antepasados conforman una instantánea o versión de tu proyecto. |
| branch | rama | Es un nombre que actúa como puntero a un commit concreto dentro de tu repositorio .git |
| clone | clonar, copiar | Consiste en traerme a local un repositorio remoto completo, creando un duplicado del mismo para poder trabajar en él. |
| tree graph | grafo en árbol | Es una representación gráfica que refleja el árbol de conexiones entre los dos tipos de objetos que hay dentro de .git, los objetos fichero (blob) y los objetos directorio (tree). |
| blob (binary large object) | fichero binario | Es como llama git a todos los ficheros que tiene bajo .git, y que resultan ser casi siempre binario, por eso los llama blob’s |
| tree | árbol | Es como llama git a todos los objetos directorio o contenedores que tiene bajo .git |
| fetch | traer | Pedimos la última información de un remote, sin transferencia de archivos. Sirve para comprobar si hay algún cambio disponible. |
| merge | fusión | Comando que realiza una fusión a tres bandas entre las dos últimas instantáneas de cada branch y el ancestro común a ambas, creando un nuevo commit con los cambios mezclados |
| pull | tirar | Comando que para extraer y descargar contenido desde un repositorio remoto y actualizar al instante el repositorio local para reflejarlo. En realidad no es más que un git fetch segido de un git merge |
| push | empujar | Se usa para cargar contenido desde mi repositorio local hacia un repositorio remoto. El envío es la forma de transferir commits desde tu repositorio local a un repositorio remoto |
| stage | etapa | Durante un merge se identifican las entradas en el Index de los archivos con una combinación de su ruta de archivo y un número de stage para poder resolver posibles conflictos |
Hablando de documentación, además de este apunte te recomiendo la Cheatsheet en Español o la Visual Git Cheat Sheet o este pequeño Guía burros o la documentación oficial o si te vas a cualqueir buscador en internet vas a encontrar cientos de videos, tutoriales y documentos.
Instalación de Git
Para empezar, te recomiendo que siempre te instales la versión de la línea de comandos (programa git) y que apuestes por uno de los clientes GUI anteriores, el que más te guste, lo descargues y lo instales en tu ordenador.
- Aquí tienes una pequeña guía para instalar
giten línea de comandos en Linux, Windows y Mac.
Una vez que lo tengas instalado, comprueba que funciona:
➜ ~ > git
usage: git [--version] [--help] [-C <path>] [-c <name>=<value>]
[--exec-path[=<path>]] [--html-path] [--man-path] [--info-path]
[-p | --paginate | -P | --no-pager] [--no-replace-objects] [--bare]
[--git-dir=<path>] [--work-tree=<path>] [--namespace=<name>]
<command> [<args>]
:
➜ ~ > git --version
git version 2.24.3 (Apple Git-128)
Ahora al lio, este apunte está inspirado desde otro en inglés que me gustó mucho, git from the inside out. Considera el mío como un fork ampliado y mejorado, con más detalle y explicaciones más cercanas y sencillas. Por supuesto no me quiero olvidar de dar crédito a su Autora Mary Rose Cook, muchas gracias desde aquí!.
GIT desde el interior
Asumo que has dedicado algo de tiempo a entender más o menos de qué va esto y quieres usarlo para el control de versiones de tus proyectos. Git será fácil una vez que le hayas dedicado algo de tiempo.
Ha quedado patente después de unos añitos que supera a otras herramientas de control de versiones (SCM-Source code management) como Subversion, CVS, Perforce y ClearCase por sus características como la ramificación local (branches), las áreas de preparación (staging areas) y los múltiples flujos de trabajo.
Veremos el tree graph, la estructura gráfica que refleja el árbol de conexiones entre ficheros que sustenta a Git. Vamos a empezar creando un único proyecto en local y cómo los comandos van afectando a dicha estructura gráfica.
Creación de un proyecto
Desde la línea de comandos creamos el directorio alpha, porque cada proyecto debe estar en un directorio distinto.
➜ ~ > clear
➜ ~ > mkdir alpha
Nos metemos en alpha y creamos un (sub)directorio data. Dentro creamos un archivo llamado letter.txt que contiene el caracter a:
➜ ~ > cd alpha
➜ alpha > mkdir data
➜ alpha > echo 'a' > data/letter.txt
Aquí tenemos el resultado final:
alpha
└── data
└── letter.txt <- Contiene la letra 'a'
Inicializamos el repositorio
Un repositorio GIT es una carpeta dedicada dentro de tu proyecto (directorio). Este repositorio es local y contendrá todos los archivos que queremos ‘versionar’.
➜ alpha > git init
Initialized empty Git repository
El comando git init crea el subdirectorio .git con una estructura inicial, formándose así un nuevo repositorio local, definiendo la configuración de Git y la historia del proyecto. Son archivos ordinarios, sin ninguna magia, el usuario puede leerlos y editarlos con un editor de texto o un shell.
El directorio alpha tiene ahora este aspecto:
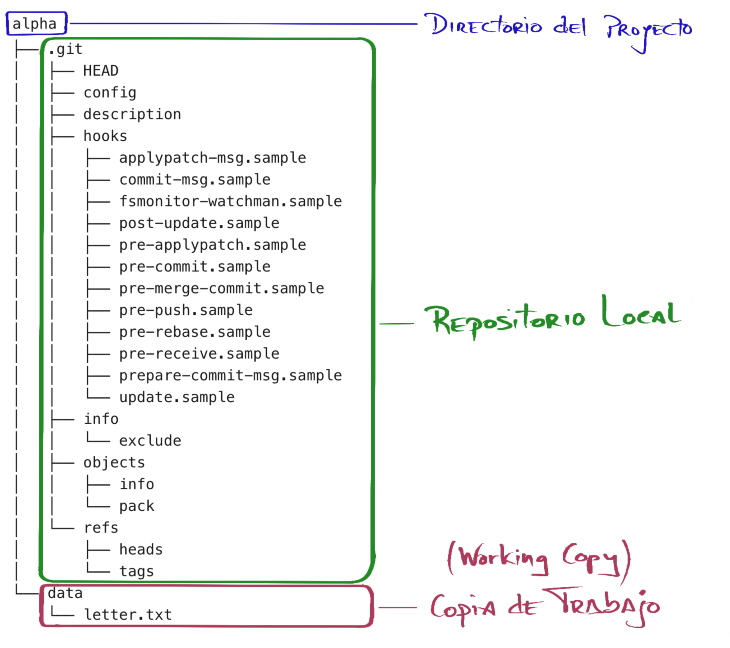
Lo que hay dentro de .git es propiedad de GIT (ahí van a estar todas las versiones del proyecto y todo dentro de él se manipula usando el comando). El resto de ficheros (fuera de .git) se han convertido en la que GIT llama la working copy y son propiedad del usuario.
Añadimos algunos ficheros
Nuestro repositorio local empieza vacío (excepto los ficheros mínimos que vimos antes). Vamos a empezar a pasarle ficheros, es decir, vamos a añadir ficheros a GIT!!! desde la Working Copy.
Añadimos el fichero letter.txt a GIT
➜ alpha git:(master) ✗ > git add data/letter.txt
Ejecutar git add sobre data/letter.txt tiene dos efectos
PRIMERO, se crea un fichero “blob” (binary large object) en el directorio .git/objects/. Se trata del contenido comprimido de data/letter.txt (lo comprime con zlib). El nombre del fichero blob se fabrica con el resultado de hacer un hash de tipo SHA-1 sobre su contenido. Hacer un hash de un fichero significa ejecutar un programa que lo convierte en un trozo de texto más pequeño 1 (40bytes) que identifica de forma exclusiva 2 al original.
El fichero se sitúa en una subcarpeta con los primeros 2 caracteres de su nombre (.git/objects/2e/) y dentro de dicha carpeta está el fichero, con un nombre con el resto de los 38 caracteres, con todo el contenido dentro en formato comprimido.
alpha
├── .git
: :
│ ├── objects
│ │ ├── 2e
│ │ │ └── 65efe2a145dda7ee51d1741299f848e5bf752e <- versión comprimida de letter.txt con a
Fíjate en que al añadir un archivo a Git se guarda su contenido en el directorio directorio objects, por lo tanto podrías incluso borrarlo de tu working copy, data/carta.txt, que siempre tendrás opción de recuperarlo desde git…
SEGUNDO, git add añade el archivo al Index, .git/index. El index es una lista que contiene todos los archivos a los que hemos pedido hacer seguimiento/rastreo.
Se utiliza para controlar quién está en la staging area (zona de espera), entre tu working copy (directorio de trabajo) y el futuro commit. Puedes usar el index para construir un conjunto de cambios sobre los que más adelante harás un commit. Cuando lo hagas, lo que se confirma es lo que está actualmente en el index, no lo que está en tu working copy.
En cada unad e las líneas del archivo (.git/index) encontrarás una referencia a un archivo rastreado, con la información del hash de su contenido. Así que ahora nuestro fichero tiene…:
➜ ~ > cat alpha/.git/index
DIRC`~ٳ���`~ٳ�����}���.e��Eݧ�Q�t��H�u.data/letter.txt���;V��JަI�(7/7�%
¿Pero qué es eso?. recuerda con los ficheros se guardan como blobs, en formato binario, no puedes verlos como ficheros de texto, hay que usar otro tipo de comandos para ver su contenido.
➜ alpha git:(master) ✗ > git ls-files --stage
100644 2e65efe2a145dda7ee51d1741299f848e5bf752e 0 data/letter.txt
➜ alpha git:(master) ✗ > git status
:
Changes to be committed:
:
new file: data/letter.txt
Creamos un segundo fichero, number.txt
Creamos un fichero llamado data/number.txt con un contenido 1234.
➜ alpha git:(master) ✗ > echo 1234 > data/number.txt
En la working copy tenemos:
alpha
└── data
├── letter.txt
└── number.txt
Añadimos el fichero number.txt a GIT
El usuario añade el fichero number.txt a GIT
➜ alpha git:(master) ✗ > git add data
Como vimos antes, de nuevo, el comando git add crea un objeto blob que contiene el contenido de data/number.txt. Añade una entrada al Index sobre datos/número.txt que apunta al blob. Este es el nuevo contenido del Index (.git/index):
➜ alpha git:(master) ✗ > git ls-files --stage
100644 2e65efe2a145dda7ee51d1741299f848e5bf752e 0 data/letter.txt
100644 274c0052dd5408f8ae2bc8440029ff67d79bc5c3 0 data/number.txt
Observa que sólo aparecen los archivos del directorio data, aunque el usuario haya ejecutado git add data el directorio data no aparece por ningún sitio… paciencia.
Vamos a hacer un pequeño cambio. Cuando el usuario creó originalmente datos/número.txt, quería escribir 1, no 1234.
➜ alpha git:(master) ✗ > echo '1' > data/number.txt
Añadimos de nuevo number.txt a Git.
➜ alpha git:(master) ✗ > git add data
Fíjate que tenemos 3 blobs… ¿podrías decirme porqué?.
alpha
├── .git
│ ├── objects
│ │ ├── 27
│ │ │ └── 4c0052dd5408f8ae2bc8440029ff67d79bc5c3 <- number.txt con 1234
│ │ ├── 2e
│ │ │ └── 65efe2a145dda7ee51d1741299f848e5bf752e <- letter.txt con a
│ │ ├── 56
│ │ │ └── a6051ca2b02b04ef92d5150c9ef600403cb1de <- number.txt con 1
:
└── data
├── letter.txt
└── number.txt
Además, en el Index solo aparecen dos ficheros ¿Podrías decirme porqué?
➜ alpha git:(master) ✗ > git ls-files --stage
100644 2e65efe2a145dda7ee51d1741299f848e5bf752e 0 data/letter.txt
100644 56a6051ca2b02b04ef92d5150c9ef600403cb1de 0 data/number.txt
Respuesta:
Al cambiar datos/número.txt y hacer un add estamos añadiendo el “nuevo” archivo al Index, se crea un nuevo blob con el nuevo contenido y además actualiza la entrada de “datos/número.txt” para que apunte al nuevo blob. El Index en la staging area contiene un puntero a la última versión de cada archivo agregado.
Primer commit
Recuerda que git commit trabaja en tu repositorio local (no en GitHub). Hacer un commit consiste en “confirmar” lo que tenemos en el staging area para llevarlo a tu repositorio local, capturando una instantánea de los ficheros preparados en la staging area y guardándola como una versión. Estos commits pueden considerarse como versiones “seguras” de un proyecto. Al hacer un commit es obligatorio describirlo, y se hace con el argumento -m "mensaje descriptivo sobre este commit".
En este tutorial aprovechamos el mensaje del commit como una nomenclatura sencilla para seguirlo. A este primer commit lo llamaremos a1. El usuario hace el commit a1. Git imprime algunos datos sobre el mismo que tendrán sentido en breve.
➜ alpha git:(master) ✗ > git commit -m 'a1'
[master (root-commit) 8c80d78] a1
2 files changed, 2 insertions(+)
create mode 100644 data/letter.txt
create mode 100644 data/number.txt
Los tres pasos de un “Commit”
Cuando haces un commit ocurren tres cosas (más info aquí):
- Se crea un “tree graph” representando los directorios y ficheros afectados. En este ejemplo que nos ocupa vemos que se crean dos objetos de tipo
treevinculados a dos objetos ya existentes de tipoblob. - Se crea un objeto commit con tocda la información sobre el mismo, el autor, el committer, el comentario y por último el puntero al objeto
treeraíz del “tree graph” - Se conecta la branch actual (master) para que apunte al objeto commit recién creado.
│ ├── objects
│ │ ├── 0e
│ │ │ └── ed12..0b74 <- nuevo: TREE >--------+ <-+
│ │ ├── 27 | |
│ │ │ └── 4c00..c5c3 <- number.txt con 1234 <-+ |
│ │ ├── 2e | |
│ │ │ └── 65ef..752e <- letter.txt con a | |
│ │ ├── 56 | |
│ │ │ └── a605..b1de <- number.txt con 1 <----+ |
│ │ ├── 8c |
│ │ │ └── 80d7..784c <- nuevo: COMMIT >--+ |
│ │ ├── ff | |
│ │ │ └── e298..6db4 <- nuevo: TREE <----+ -(data)-+
Se crea el “tree graph”
Git registra el estado actual del proyecto creando un árbol virtual a partir del Index. Este árbol se denomina el “tree graph” y contiene la información necesaria sobre la ubicación y contenido de los punteros (objetos tree) y los archivos (objetos blob). Por lo tanto, el “tree graph” se compone de dos tipos de objetos:
- Los blobs, que son los archivos que habíamos añadido con
git add - Los trees, se usan para apuntar a otros objetos (por ejemplo los subdirectorios que contienen archivos)
Veamos uno de los objetos tree que se ha creado: 0eed...0b74. Este fichero contiene un puntero a los archivos dentro del directorio data:
➜ alpha git:(master) > git --no-pager show 0eed
tree 0eed
letter.txt
number.txt
➜ alpha git:(master) > git --no-pager cat-file -p 0eed
100644 blob 2e65efe2a145dda7ee51d1741299f848e5bf752e letter.txt <- contiene 'a'
100644 blob 56a6051ca2b02b04ef92d5150c9ef600403cb1de number.txt <- contiene '1'
La primera línea registra todo lo necesario para reproducir data/letter.txt: los permisos del archivo, su tipo (blob), el hash del fichero y el nombre del archivo. La segunda línea lo mismo para reproducir data/number.txt.
Veamos el otro puntero tree: ffe2...6db4. Es el del directorio raíz del proyecto (alpha), por lo tanto contiene la el puntero al objeto anterior (el que apunta a data), el otro objeto de tipo tree que se acababa de crear, 0eed.
➜ alpha git:(master) > git --no-pager show ffe2
tree ffe2
data/
➜ alpha git:(master) > git --no-pager cat-file -p ffe2
040000 tree 0eed1217a2947f4930583229987d90fe5e8e0b74 data
Tiene una línea apuntando al directorio data. Contiene el valor 040000 (tipoe directorio), el tipo (tree), el hash del objeto tree que vimos antes y el nombre del directorio data.

Lo mismo visto gráficamente nos muestra cómo el objeto tree raíz (root) apunta al objeto tree data que apunta a los dos objetos blobs data/letter.txt y datos/número.txt.
Se crea el objeto Commit
Además de los dos objetos (ficheros) tree que componen el tree graph, se ha creado un nuevo objeto (fichero) de tipo commit que también se guarda en .git/objects/:
➜ alpha git:(master) > git --no-pager cat-file -p 8c80
tree ffe298c3ce8bb07326f888907996eaa48d266db4
author Luis Palacios <luis@mail.com> 1618933917 +0200
committer Luis Palacios <luis@mail.com> 1618933917 +0200
a1
La primera línea apunta al inicio del tree graph, al objeto raíz raíz (root) de la working copy, es decir, el directorio alpha. La última línea es el mensaje del commit.


Conecta la branch actual con el commit
La tercera acción consiste en conectar la branch actual con el objeto commit recién creado. GIT saca su nombre de la branch actual en el archivo .git/HEAD:
➜ alpha git:(master) ✗ cat .git/HEAD
ref: refs/heads/master
Vemos que HEAD (una referencia) está apuntando a master (otra referencia), por lo tanto master es la branch actual. Las referencias son etiquetas utilizada por Git o por el usuario para identificar un commit. El archivo que representa la referencia master debe contener un puntero al hash del commit (8c80) y dicha conexión se crea en el archivo .git/refs/heads/master
➜ alpha git:(master) ✗ cat .git/refs/heads/master
8c80d787e43ca98d7a3f8465a5f323684899784c
(No lo he dicho antes, pero todos ciertos HASHs que estás viendo no van a coincidir con los tuyos, los objetos con contenido como los blobs y los trees siempre hacen un hash al mismo valor, pero los commits cambian porque contienen fechas y nombres distintos)
Ahora que tenemos todo conectado vamos a añadir HEAD y master a nuestro gráfico:
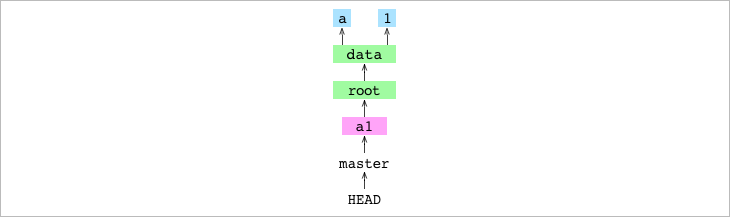
Ya tenemos todo conectado: HEAD apunta a master con un hash apuntando al objeto commit, que apunta al objeto root (alpha) que a su vez apunta a data que apunta a letter.txty number.txt.
Hacemo un commit adicional
Ahora vamos a ver qué pasa cuando se hace un commit que no es el primer commit.
Nos fijamos en la siguiente gráfica que muestra el estado después del primer commit a1. Enseño a la derecha a quién apunta el Index y a la izquierda cual es el contenido de la working copy (qué hay actualmente fuera de Git, en la working copy)
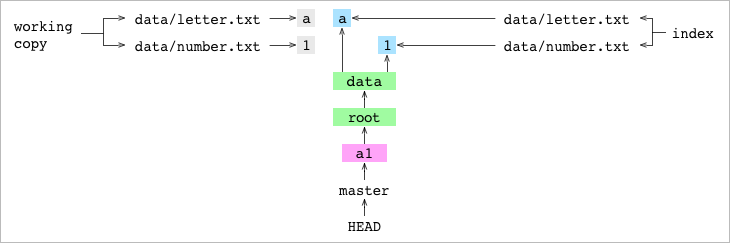
Fíjate que los ficheros que están en la copia de trabajo y los blob’s que se apuntan desde el Index y los que se apuntan desde el commit a1 apuntan todos a ficheros que tienen exáctamente el mismo contenido (los diferentes data/letter.txt y data/number.txt comparten contenido). Pero son ficheros disntintos. El Index y el commit HEAD utilizan hashes para referirse a los objetos blob pero el contenido de la copia de trabajo se almacena como texto en un lugar distinto (fuera de .git)
Vamos a cambiar una cosilla… vamos a cambiar el contenido del fichero number.txt con un ‘2’.
➜ alpha git:(master) > echo 2 > data/number.txt
Esto ocurre en la working copy, pero se deja el Index y el commit (HEAD) intactos.
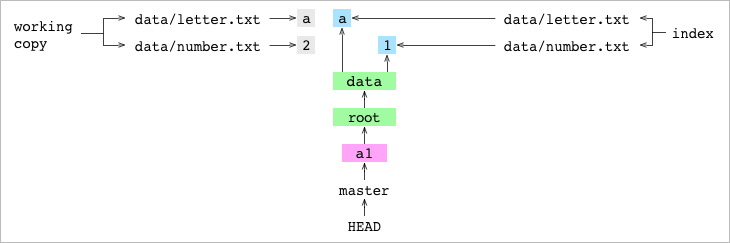
Añado number.txt a la staging area (Index), por lo tanto se añade un nuevo blob que contiene un 2 al directorio .git/objects/ y además la entrada del Index apunta a este nuevo blob.
➜ alpha git:(master) ✗ > git add data/number.txt
Ahora number.txt tiene un 2 en la working copy y en el Index (staging area)
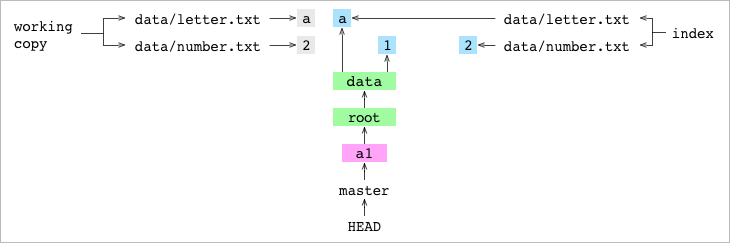
Ejecuto el segundo commit.
➜ alpha git:(master) ✗ > git commit -m 'a2'
[master 850918e] a2
1 file changed, 1 insertion(+), 1 deletion(-)
Al hacer el commit los pasos son los mismos que la vez anteriore.
Primero se crea un NUEVO TREE GRAPH para representar el contenido del Index. Un nuevo BLOB para el tree data (porque data/number.txt ha cambiado el tree antigo ya nos nos vale)
➜ alpha git:(master) > git ls-files --stage
100644 2e65efe2a145dda7ee51d1741299f848e5bf752e 0 data/letter.txt <-- reutiliza blob. Contiene 'a'
100644 0cfbf08886fca9a91cb753ec8734c84fcbe52c9f 0 data/number.txt <== nuevo blob, contiene '2'
Un segundo BLOB nuevo para root que apunte al nuevo blob de data recién creado
➜ alpha git:(master) > git --no-pager cat-file -p fbfd
040000 tree b580fd166d4b75627577d2632ca7d806e07639d8 data
Segundo, se crea un nuevo objeto commit.
➜ alpha git:(master) > git --no-pager cat-file -p 8509
tree fbfdfef0e0ad86ff61aedcc0a0d5643f7a54fea6
parent 8c80d787e43ca98d7a3f8465a5f323684899784c
author Luis Palacios <luis@gmail.com> 1619459710 +0200
committer Luis Palacios <luis@gmail.com> 1619459710 +0200
a2
La primera línea del commit apunta al nuevo objeto tree root, la segunda línea apunta al commit anterior a1 (para poder encontrar el commit padre GIT se fue a HEAD y lo siguió hasta que dió con el hash del commit de a1)
Tercero, el contenido de la Branch master pasa a apuntar al hash del nuevo commit (a2)
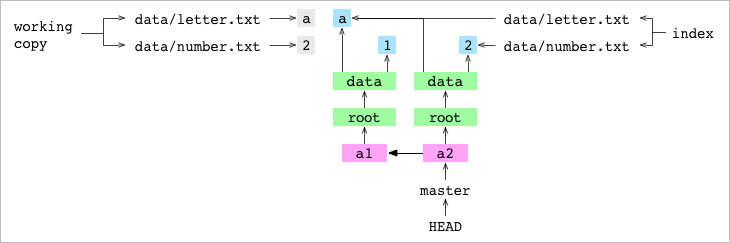

Veamos la gráfica sin reflejar los datos de los ficheros:
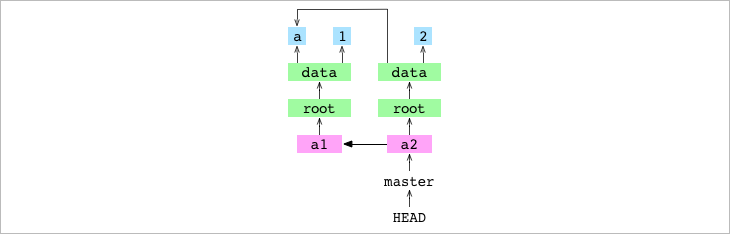
Características de los tree graphs
Veamos algunos conceptos interesantes respecto a los árboles dentro del directorio objects/
-
El contenido se almacena como un árbol de objetos. Esto significa que en la base de datos de objetos sólo se almacenan las diferencias. Observa el gráfico de arriba. El commit
a2reutiliza el blobletter.txt con 'a'que se hizo antes del commita1. Del mismo modo, si un directorio completo no cambia de un commit a otro, su árbol y todos los blobs y árboles por debajo se reutilizan. Generalmente, hay pocos cambios de contenido entre commits, por lo que GIT puede almacenar grandes historiales de commits ahorrando mucho espacio. -
Cada commit tiene un padre. Esto significa que un repositorio puede almacenar la historia completa de las modificaciones y versiones que ha tenido un proyecto.
-
Las referencias son puntos de entrada a una parte del historial de commits. Esto significa que los commits pueden tener nombres significativos que nos digan algo interesante. El usuario organiza su trabajo en linajes que son significativos para su proyecto con referencias concretas como
fijo-para-el-bug-376. Git se reserva y emplea referencias simbólicas comoHEAD,MERGE_HEADyFETCH_HEADpara soportar comandos que manipulan el historial de los commits. -
Los nodos en el directorio
objects/son inmutables. Esto significa que el contenido se edita, no se borra. Cada objeto que se ha añadido y cada commit que se ha hecho está en algún lugar del directorioobjects3. -
Las referencias son mutables. Por lo tanto, el significado de una ref puede cambiar. El commit al que apunta
masterpuede estar apuntando a una versión del proyecto ahora pero apuntar a otra dentro de un rato.
Características sobre el histórico
Veamos algunos conceptos interesantes respecto a la facilidad o dificultad de recuperar un determinado commit (ir a esa versión) que también podemos describir como “acceder a un momento en el tiempo” o moverse por la historia del proyecto.
-
La copia de trabajo y los commits a los que apuntan las referencias (
refs) están fácilmente disponibles, pero otros commits (sin referencias) no lo están. Esto significa que la historia reciente es más fácil de recuperar. -
La copia de trabajo es el punto de la historia más fácil de recuperar porque está en la raíz de tu directorio del proyecto. Acceder a la working copy ni siquiera requiere un comando Git. También es el punto menos permanente del historial. El usuario puede hacer una docena de versiones de un archivo que Git no registrará ninguna a menos que que se le añadan.
-
El commit al que apunta
HEADes muy fácil de recuperar. Normalmente apunta a la punta de la Branch que se ha extraido (checkout). Si hemos modificado algo en la working copy y queremos volver a la versíon deHEADel usuario puede hacer ungit stash(esconder la modificación en la working copy 4), examina lo que tenía y luego hace ungit stash poppara volver a la versión de la copia de trabajo. Al mismo tiempo,HEADes la referencia que cambia con más frecuencia. -
El commit al que apunta una
ref(referencia) concreta es fácil de recuperar. El usuario puede simplemente hacer un checkout de esa Branch. La punta de una Branch cambia con menos frecuencia queHEAD, pero con la suficiente frecuencia como para que tuviese sentido asignarle un nombre en su momento. -
Es difícil recordar un commit que no esté señalado por ninguna
ref, cuanto más se aleje el usuario de una referencia, más difícil le resultará reconstruir el significado de un commit (¿porqué hice aquel commit en su momento?). Por otro lado, cuanto más se remonte, menos probable es que alguien haya cambiado la historia desde la última vez que miró 5.
Checkout (git checkout)
El comando git checkout permite desplazarte por las diferentes punteros o versiones almacenados en .git, o dicho de otra forma, por las Branchs o los Commit’s. “Checkout” significa “comprobar, consultar, revisar” y conceptualmente es lo que hacemos, le pedimos a git “revisar” y lo que hace es sacar un contenido en el tiempo desde .git y lo copia al working directory.
Puede usarse para cualquier de las dos opciones siguientes:
-
cambiarse a un commit concreto.
-
cambiarse a una branch
Digo “cambiarse” porque así se entiendo mejor, visualmente estamos desplazándonos por el historial que tenemos en git y le estamos pidiendo “cambia esta branch o commit”, sácala de git, que quiero revisarla…
Checkout de un commit
Veamos un ejemplo de checkout de un commit específico. Ahora mismo tu HEAD está apuntando a través de master al commit a2 y vamos a hacer un checkout de a2, que no tiene ningún sentido práctico, pero nos sirve para ver qué ocurre y para aprender.
➜ alpha git:(master) > git checkout 850918 <-- Este es el hash del commit `a2`
Note: switching to '850918'.
You are in 'detached HEAD' state...
HEAD is now at 850918e a2
Nota: En tu caso el hash que veas será distinto (búscalo con git log)
Una vez hecho utilizando su hash, provoca que ocurran cuatro cosas:
- 1. Git obtiene el commit
a2y el tree graph al que apunta. - 2. Saca los archivos que hay en el tree graph y los copia a la working copy desde
.git/. En nuestro caso no hay ningún cambio porque como decía ya teníamos ese contenido, ecuerda queHEADya estaba apuntando a través demasteral commita2. - 3. GIT escribe las entradas de los archivos del tree graph en el Index. Una vez más, ningún cambio, el Index ya tiene el contenido del commit
a2. - 4. El contenido de
HEADse establece en el hash del commita2.
➜ alpha git:(850918e) > cat .git/HEAD
850918e87cb094f6f01f73d971619ed79f8cfb43
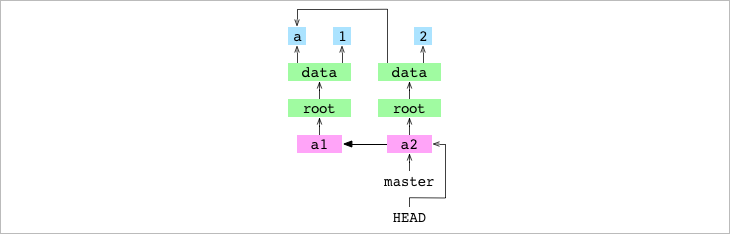
Aquí está la diferencia, HEAD apunta a un commit en vez de a una branch !!! y cuando HEAD tiene el hash de un commit en vez de la referencia a la branch, lo que hace es poner al repositorio en el estado de detached HEAD (HEAD separado. Mira en el gráfico de abajo que HEAD apunta directamente al commit a2, en lugar de apuntar a la branch master
Si ahora tocamos la working copy, le pongo un 3 a number.txt, y hacemos un commit.
➜ alpha git:(850918e) > echo 3 > data/number.txt
➜ alpha git:(850918e) ✗ > git add data/number.txt
➜ alpha git:(850918e) ✗ > git commit -m 'a3'
[detached HEAD 92ffe65] a3
1 file changed, 1 insertion(+), 1 deletion(-)
GIT se va a HEAD para obtener el que sería el padre del commit y lo que se encuentra y devuelve es el hash al commit a2. Actualiza HEAD para que apunte directamente al hash del nuevo commit a3. Pero el repositorio sigue en el estado de detached HEAD. No estamos en una branch porque ningún commit apunta a a3 o sus futuros descencientes, por lo que sería fácil perderlos.
A partir de ahora, voy a omitir los tree y blob en la mayoría de los diagramas gráficos para simplificar.
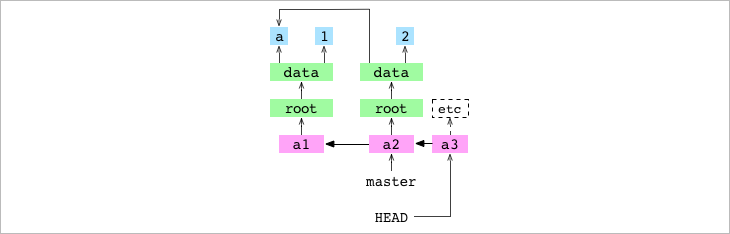
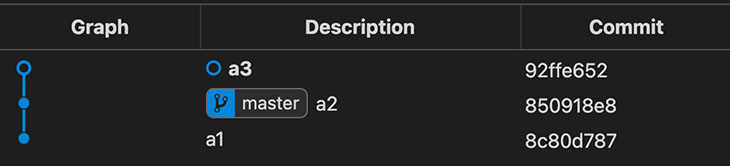
Crear una Branch
Creamos una nueva branch llamada deputy. Simplemente crea un nuevo archivo en .git/refs/heads/deputy que contiene el hash al que apunta HEAD, en este caso el hash del commit a3.
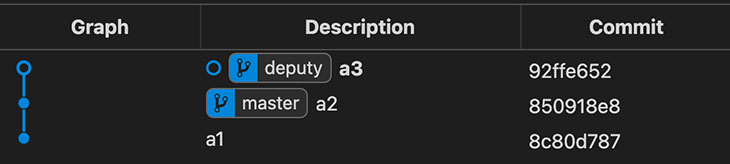
➜ alpha git:(92ffe65) > git branch deputy
Nota: Las Branches no son más que referencias (refs) y las referencias no son más que ficheros de texto, lo cual contribuye aún más a que git sea tan ligero.
La creación de deputy pone al commit a3 de vuelta de forma segura en una Branch, pero ojo porque HEAD sigue estando separada porque sigue apuntando directamente a un commit.
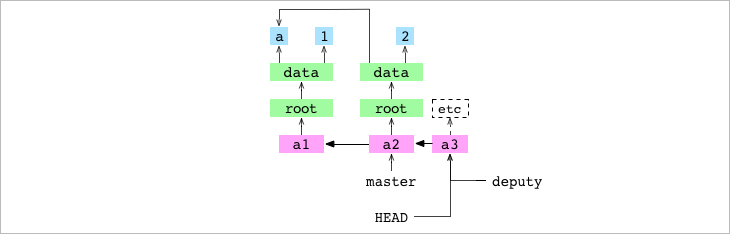
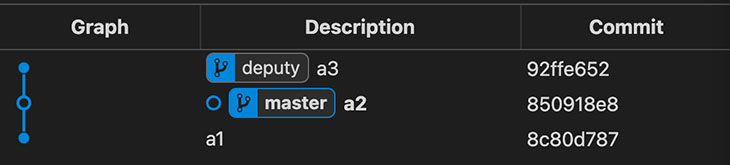
Checkout de una Branch
Vamos a ver qué pasa si le pedimos a GIT que haga un checkout de la branch master.
➜ alpha git:(92ffe65) > git checkout master
Previous HEAD position was 92ffe65 a3
Switched to branch 'master'
➜ alpha git:(master) >
Primero, GIT consigue el commit a2 al que apunta master y por tanto consigue el tree graph (recuerda, estructura de subdirectorios y archivos) de dicho commit.
En segundo lugar, GIT saca los archivos desde el tree graph y los copia a la working copy (desde .git). Eso provoca que el contenido en la working copy de data/number.txt pase de ser 3 a 2.
En tercer lugar, Git escribe las entradas de los archivos en el tree graph en el Index. Esto actualiza la entrada de datos/número.txt con el hash del blob 2
Cuarto, GIT hace que HEAD apunte a master, cambiando su contenido desde el hash anterior a refs/heads/master.
➜ alpha git:(master) > cat .git/HEAD
ref: refs/heads/master
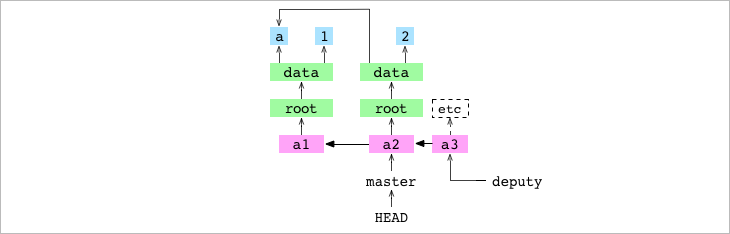 |
|---|
Checkout de master que apuntaba a a2 |
Checkout de branch incompatible
Vamos a ver un caso curioso, hacer un checkout de una branch que es incompatible con nuestra working copy. Si intentamos introducir los comandos siguientes, GIT nos avisa de una incompatibilidad y aborta el checkout.
➜ alpha git:(master) > echo '789' > data/number.txt
➜ alpha git:(master) ✗ > git checkout deputy
error: Your local changes to the following files would be overwritten by checkout:
data/number.txt
Please commit your changes or stash them before you switch branches.
Aborting
➜ alpha git:(master) ✗ >
Hemos modificado el contenido de data/number.txt con 789 y después intentado hacer un checkout de la branch deputy. Git aborta este último para evitar que perdamos dicho cambioen number.txten nuestra copia local.
HEAD apunta al master que apunta a a2 donde data/number.txt contiene un 2. La branch deputy apunta a a3 donde data/number.txt contiene un 3. La copia de trabajo tiene data/number.txt con 789. Todas estas versiones son diferentes y las diferencias deben ser resueltas.
GIT podría haber ignorado el rpoblema pero está diseñado para evitar la pérdida de datos. Otra opción es que GIT hubiese fusionado la copy version con la versión de deputy, pero sería un poco chapuza, así que aborta…
El usuario se da cuenta que no quería dicha modificación, vuelve a poner el contenido original e intenta cambiarse a la branch deputy.
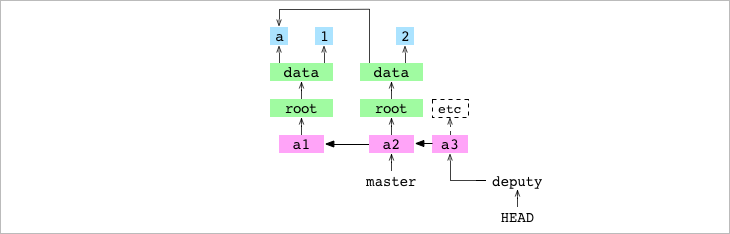
➜ alpha git:(master) ✗ > echo '2' > data/number.txt
➜ alpha git:(master) > git checkout deputy
Switched to branch 'deputy'
➜ alpha git:(deputy) >
Ahora sí que funciona, no hay nada que se vaya a perder, por lo tanto GIT acepta el checkout de deputy y cambia al mismo, lo extrae, lo copia a la workign copy y hace que HEADa punte a él.
Merge de un antepasado
Vamos a adentrarnos en una de las funciones más interesantes de GIT, el poder “fusionar” datos entre commits.
Si recordamos, eshemos extraído la branch deputy, nos encontramos en ella. Vamos a ver qué pasa si le pedimos a GIT que se traiga y fusione los datos de master en esta branch en la que estoy (deputy).
➜ alpha git:(deputy) > git merge master
Already up to date.
El intento consiste en hacer una merge de algo del pasado, master, dentro de deputy. El merge de dos branchs significa fusionar dos commits. El primer commit receptor es siempre en el que nos encontramos (deputy). El segundo commit es el emisor, aquel que indicamos en el comando git merge (master). En resumen, pedimos que el contenido de master se fusione dentro de deputy.
En este caso GIT no hace nada, nos dice Already up-to-date. (ya estoy al día).
Lógico, el commit emisor (dador) es un antepasado del commit receptor, GIT no tiene que hacer nada porque el commit de deputy venía de master (a2), nació desde él, por lo tanto no necesita que le incorporemos nada, porque no hay nada nuevo a incorporar.
Merge de un descendiente
¿Pero qué pasa si intentamos hacer lo contrario?, por ejemplo fusionar algo del futuro (algo que se ha hecho un commit en el futuro y quiero llevarlo a una copia del pasado). Para provocarlo, vámonos a la otra branch, cambiamos a master.
➜ alpha git:(deputy) > git checkout master
Switched to branch 'master'
➜ alpha git:(master) >
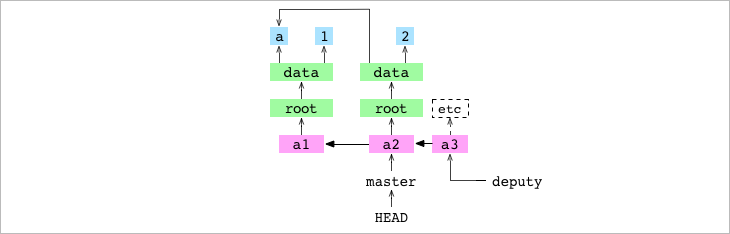
Ahora vamos a intentar fusionar algo que se hizo en el futuro (desde) deputy dentro de master. El commit receptor es en el que nos encontramos (master). El commit emisor es (deputy) (indicado en el comando), pedimos que el contenido de deputy se fusione dentro de master.
➜ alpha git:(master) > git merge deputy
Updating 850918e..92ffe65
Fast-forward
data/number.txt | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
➜ alpha git:(master) >
Se hace merge de deputy en master. GIT se da cuenta de que el commit receptor a2, es más viejo que el commit emisor, a3, por lo tanto acepta el merge, y provoca el fast-forward merge (avanzamos msater hacia el futuro, provocamos que master se ponga a la altura temporal de a3 con las modificaciones que este commit contenga). Tan sencillo como que ahora master apunta a a3: Obtiene el commit del emisor (dador) y el tree graph al que apunta. Se sacan y escriben las entradas de los archivos desde el tree graph, se copian al working copy y al Index y se hace que master se “adelante” apuntando a a3.
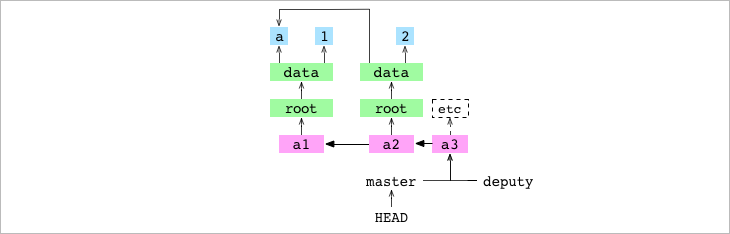
Las series de commits en el gráfico se interpretan como una serie de cambios realizados en el contenido del repositorio. Esto significa que, durante un merge, si el dador es un descendiente del receptor, la historia
no se modifica. Ya existe una secuencia de commits que describen el cambio a realizar: la secuencia de commits entre el receptor y el dador. Pero, aunque el historial de Git no cambia, el gráfico de Git sí cambia. La referencia concreta a la que apunta HEAD se se actualiza para apuntar al commit del dador (en este caso a3).
Merge desde linajes distintos
Vamos a ver otro caso, ahora vamos a intentar hacer un merge de dos commits que están en linajes distintos. Empezamos preparando un nuevo commit, ponemos un 4 en number.txt y hacemos un commit a4 en master.
➜ alpha git:(master) > echo '4' > data/number.txt
➜ alpha git:(master) ✗ > git add data/number.txt
➜ alpha git:(master) ✗ > git commit -m 'a4'
[master 3a8599e] a4
1 file changed, 1 insertion(+), 1 deletion(-)
➜ alpha git:(master) >
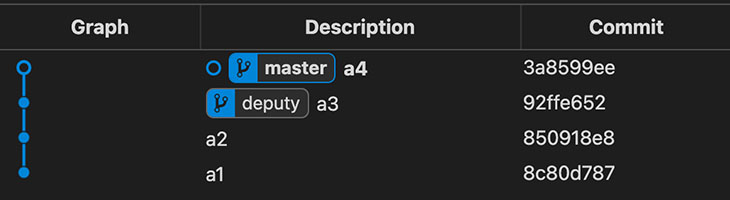 |
|---|
commit a4 en master |
Cambiamos a deputy (checkout, ponemos una b en data/letter.txt y hacemos un commit b3.
➜ alpha git:(master) > git checkout deputy
Switched to branch 'deputy'
➜ alpha git:(deputy) > echo 'b' > data/letter.txt
➜ alpha git:(deputy) ✗ > git add data/letter.txt
➜ alpha git:(deputy) ✗ > git commit -m 'b3'
[deputy ce860c7] b3
1 file changed, 1 insertion(+), 1 deletion(-)
➜ alpha git:(deputy) >
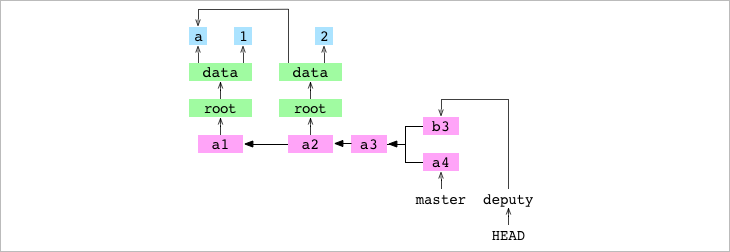
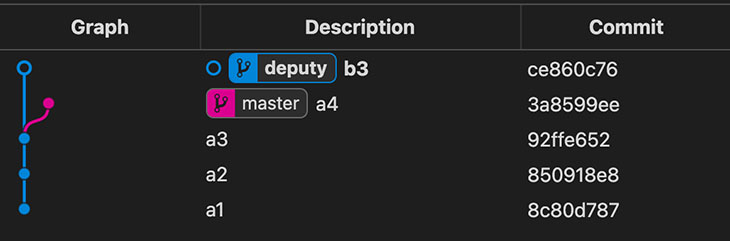
Fíjate que ambos commits (a4 y b3) parten del contenido del commit padre a3, por lo tanto:
-
Los commits pueden compartir “padres”. Eso significa que los nuevos linajes se crearon desde la misma historia (en este caso partían desde
a3) -
Los commits pueden tener múltiples padres. Esto significa que linajes separados pueden ser fusionados en un nuevo commit con dos padres con el comando
commit merge
Dicho de otra forma, si no hay conflicto (modificar mismo fichero) en ambos linajes, debería ser realtivamente sencillo fusionar ambos contenidos y crear un nuevo commit. Veamos cómo !!
➜ alpha git:(deputy) > git merge master -m 'b4'
Merge made by the 'recursive' strategy.
data/number.txt | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
➜ alpha git:(deputy) >
Recordamos, el primer commit receptor es siempre en el que nos encontramos (deputy). El segundo commit es el emisor, aquel que indicamos en el comando git merge (master).
En resumen, estamos pidiendo que el contenido de master (a4) se fusione dentro de deputy (b3). GIT descubre que están en linajes diferentes y ejecuta el merge siguiendo una estrategia “recursiva” que consiste en ocho pasos.
- Paso #1: Git escribe el hash del commit del dador (
master) en.git/MERGE_HEAD. La presencia de este archivo indica a Git que está en medio de una merge.
- Paso #2: Git encuentra el
commit base(del que partir,a3): el ancestro más reciente que tanto receptor (deputy) como dador (master) tienen en común.
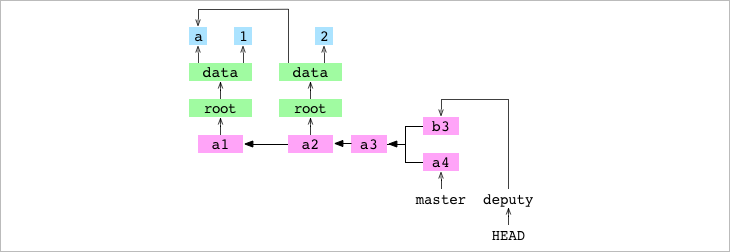
Dado que los commits tienen padres es posible encontrar el punto en el que dos linajes divergen. Git rastrea hacia atrás desde b3 para encontrar todos sus ancestros y hacia atrás desde a4 para encontrar todos sus ancestros. Encuentra el ancestro más reciente compartido por ambos linajes, a3. Ese es el commit base
- Paso #3: Git genera el Index de los commits base, receptor y dador a partir de sus tree graphs.
-
Paso #4: GIT genera un diff que combina los cambios realizados en la base por el commit receptor y el commit dador. Este diff es una lista de rutas de archivos que apuntan a un cambio: añadir, eliminar, modificar o entrar en conflicto. Git obtiene la lista de todos los archivos que aparecen en el Index base, receptor o giver. Para cada uno, compara las entradas del Index para decidir el para decidir el cambio a realizar en el archivo. Escribe una entrada correspondiente en el diff. En este caso, el diff tiene dos entradas.
-
La primera entrada es para
data/letter.txt. El contenido esaen la base,ben el receptor yaen el dador. El contenido es diferente en la base y en el receptor. Pero es el mismo en la base y en el dador. Git ve que el contenido fue modificado por el receptor, pero no por el dador. La entrada diff paradata/letter.txtes una modificación, no un conflicto. La última en modificarse fuedeputy b3con unabque se queda con versión final en el nuevo commit. -
La segunda entrada en el diff es para
data/number.txt. En este caso, el contenido es el mismo en la base y el receptor, y diferente en el dador. La entrada del diff paradata/number.txttambién es una modificación. La última en modificarse fue en el commit demaster a4con una4que se queda como versión final en el nuevo commit.
Nota: Dado que es posible encontrar el commit base de un merge, si un archivo ha cambiado desde la base sólo en el receptor o dador, Git puede resolver automáticamente el merge del mismo. Esto reduce el trabajo que debe hacer el usuario.
- Paso #5: Los cambios indicados por las entradas en el diff se aplican a
la copia de trabajo. El contenido de
data/letter.txtse establece comob(apunta al blob existente) y el contenido dedata/number.txtse establece como4(apunta al blob existente).
- Paso #6: Los cambios indicados por las entradas en el diff se aplican al Index. La entrada de
data/letter.txtestá apunta al blobby la entrada dedata/number.txtapunta al blob4.
- Paso #7: Se hace un commit al Index actualizado
➜ alpha git:(deputy) > git --no-pager cat-file -p 7f66
tree f2b663c0472703180d775c4d0f2559973ccf8503
parent 674c90926211d71b54d2651ec80b65cd20eae30d
parent cdfa1d525ef6807aa3eb9c64746dcdfac7a130d7
author Luis Palacios <luis@gmail.com> 1619523895 +0200
committer Luis Palacios <luis@gmail.com> 1619523895 +0200
b4
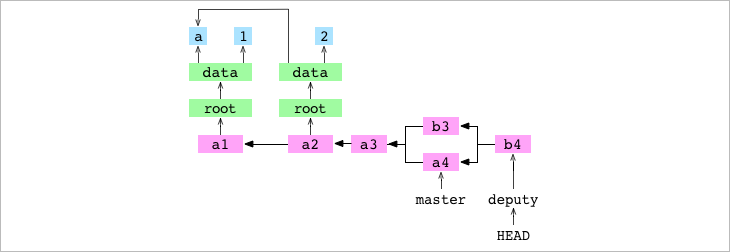
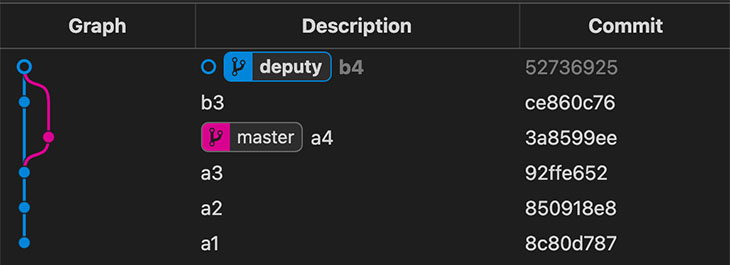
Aquí te tienes que fijar que este commit tiene dos padres.
- Paso #8: Git hace que la branch actual apunte a
deputy, al último commit.
Merge desde dos linajes con conflicto
Vamos a complicarlo un poco más, ahora vamos a intentar un merge desde dos commits de diferentes linajes donde ambos han modificado el mismo fichero.
➜ alpha git:(deputy) > git checkout master
Switched to branch 'master'
➜ alpha git:(master) > git merge deputy
Updating cdfa1d5..7f66932
Fast-forward
data/letter.txt | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
➜ alpha git:(master) >
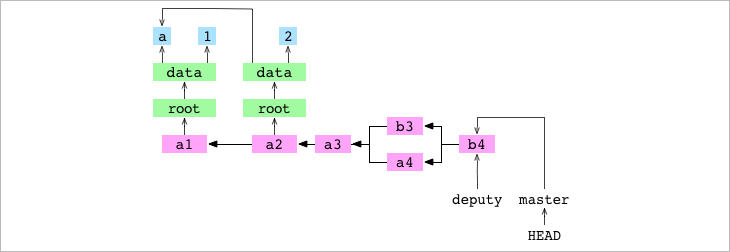
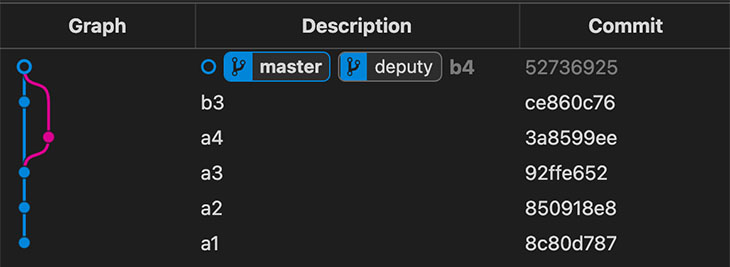
Cambiamos a master y fusionodeputy en master. Esto
adelanta a “master” al “commit” de b4. master y
deputy apuntan ahora al mismo commit.
Vamos a provocar un conflicto. Primero nos cambiamos a deputy y le ponemos un 5 a data/number.txt, hacemos el commit b5
➜ alpha git:(master) > git checkout deputy
Switched to branch 'deputy'
➜ alpha git:(deputy) > echo '5' > data/number.txt
➜ alpha git:(deputy) ✗ > git add data/number.txt
➜ alpha git:(deputy) ✗ > git commit -m 'b5'
[deputy 84675ba] b5
1 file changed, 1 insertion(+), 1 deletion(-)
➜ alpha git:(deputy) >
Después cambiamos a master, le ponemos un 6 a data/number.txt, hacemos el commit b6
➜ alpha git:(deputy) > git checkout master
Switched to branch 'master'
➜ alpha git:(master) > echo '6' > data/number.txt
➜ alpha git:(master) ✗ > git add data/number.txt
➜ alpha git:(master) ✗ > git commit -m 'b6'
[master 871d9b4] b6
1 file changed, 1 insertion(+), 1 deletion(-)
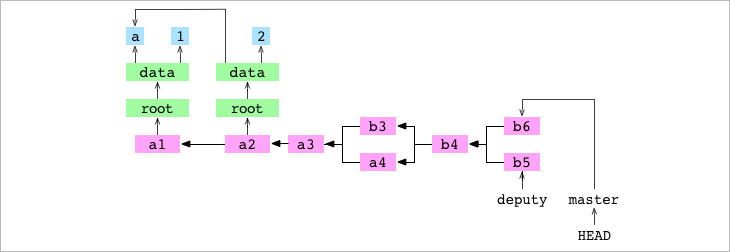
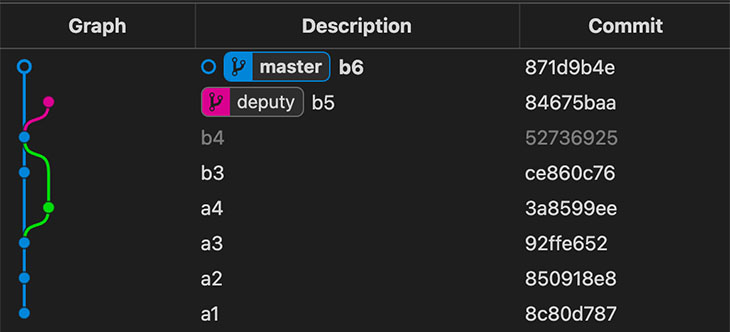
Intentamos hacer un merge de deputy (emisor) en master (receptor). Hay un conflicto y el merge se pone en pausa. El proceso para un merge conflictivo sigue los mismos seis pasos: establecer git/MERGE_HEAD, encontrar el commit base, generar el Index de los commits base, receptor y dador, crear un diff, actualizar la copia de trabajo y actualizar el Index. Pero debido al conflicto, el séptimo paso de commit y el octavo de actualización de referencia nunca se realizan.
➜ alpha git:(master) > git merge deputy
Auto-merging data/number.txt
CONFLICT (content): Merge conflict in data/number.txt
Automatic merge failed; fix conflicts and then commit the result.
➜ alpha git:(master) ✗ >
Vamos a repasar los pasos de nuevo y veamos qué ocurre
- Paso #1: Git escribe el hash de commit del dador (
deputy) en.git/MERGE_HEAD.
➜ alpha git:(master) ✗ > cat .git/MERGE_HEAD
84675baa2ee8e52a49c5a6b1b95885173a8aef42
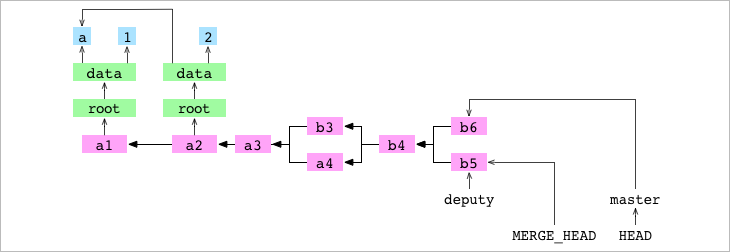
- Paso #2: Git encuentra el
commit base:b4 - Paso #3: Git genera el Index de los commits base, receptor y dador.
- Paso #4: GIT genera un diff que combina los cambios realizados en la base por el commit receptor y el commit dador. Este diff es una lista de rutas de archivos que apuntan a un cambio: añadir, eliminar, modificar o entrar en conflicto. En este caso, el diff contiene sólo una entrada:
data/number.txt. La entrada está marcada como un conflicto porque el contenido dedata/number.txtes diferente en el receptor, el dador y la base. - Paso #5: Los cambios indicados por las entradas en el diff se aplican a la copia de trabajo.
Cuando hay un conflicto GIT Git escribe ambas versiones en el archivo en la copia de trabajo. El contenido de
data/number.txtes:
➜ alpha git:(master) ✗ > cat data/number.txt
<<<<<<< HEAD
6
=======
5
>>>>>>> deputy
- Paso #6: En sexto lugar, los cambios indicados por las entradas en el diff se aplican al Index. Las entradas en el Index se identifican de forma única por una combinación de su ruta de archivo y
stage. La entrada de un fichero no conflictivo tiene unstage 0. Antes del merge, el Index tenía el siguiente aspecto (con un0como valor destage):
100644 61780798228d17af2d34fce4cfbdf35556832472 0 data/letter.txt
100644 b8626c4cff2849624fb67f87cd0ad72b163671ad 0 data/number.txt
Después del merge y en mitad del conflicto, vemos la nueva situación:
➜ alpha git:(master) ✗ > git ls-files --stage
100644 61780798228d17af2d34fce4cfbdf35556832472 0 data/letter.txt <-- No tiene problema
100644 b8626c4cff2849624fb67f87cd0ad72b163671ad 1 data/number.txt <== contiene un '4' anterior
100644 1e8b314962144c26d5e0e50fd29d2ca327864913 2 data/number.txt <== contiene un '6' conflicto <-+
100644 7ed6ff82de6bcc2a78243fc9c54d3ef5ac14da69 3 data/number.txt <== contiene un '5' conflicto <-+
El fichero number.txt ahora tiene tres entradas, la que está marcada con un 1 es el hash a la versión “base”. La que tiene un 2 es la versión del receptor y la que tiene un 3 la versión del emisor.
El merge se queda en pausa. Vamos a resolverlo escribiendo el valor que queremos que tenga number.txt.
➜ alpha git:(master) ✗ > echo '11' > data/number.txt
➜ alpha git:(master) ✗ > git add data/number.txt
➜ alpha git:(master) ✗ >
Resuelvo poniendo el contenido a mano del fichero data/number.txt, en este caso un 11 y lo añado al Index. GIT genera un nuevo blob para el fichero con el 11 y por el hecho de añadir un fichero nuevo que era el conflictivo le estamos diciendo que el conflicto se ha resuelto. GIT elimina las entradas con stages 1, 2 y 3 del Index y añade una nueva con stage 0:
➜ alpha git:(master) ✗ > git ls-files --stage
100644 61780798228d17af2d34fce4cfbdf35556832472 0 data/letter.txt
100644 b4de3947675361a7770d29b8982c407b0ec6b2a0 0 data/number.txt <-- Resuelto, versión con `11`
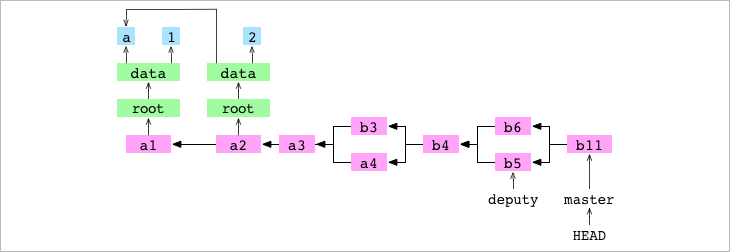
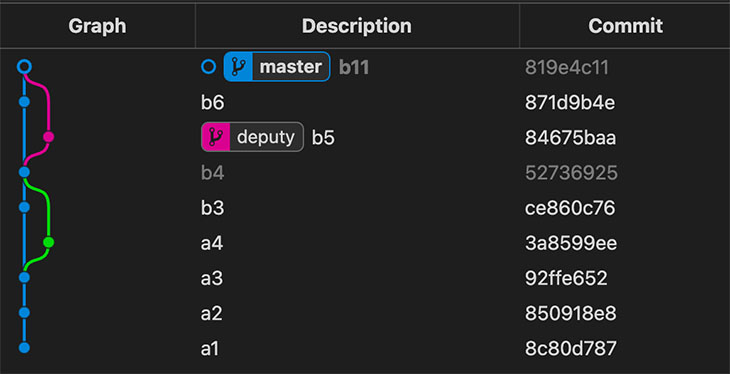
- Paso #7: Se hace un commit. GIT se da cuenta de que tiene
.git/MERGE_HEADen el repositorio, lo que le indica que hay un merge en curso. Comprueba el Index y encuentra que no hay conflictos. Crea un nuevo commit,b11, para registrar el contenido del merge resuelto. Elimina el archivo en.git/MERGE_HEADque completa el merge.
➜ alpha git:(master) ✗ > git commit -m 'b11'
[master 819e4c1] b11
➜ alpha git:(master) > git --no-pager cat-file -p 819e4c1
tree fcc4f168c1345d8c15f31acd4f34df732997a474
parent 871d9b4e8ffa2855b71b934cd77dde340901036a
parent 84675baa2ee8e52a49c5a6b1b95885173a8aef42
author Luis Palacios <luis@gmail.com> 1619532160 +0200
committer Luis Palacios <luis@gmail.com> 1619532160 +0200
b11
- Paso #8: Git hace que la branch actual,
masterapunte al nuevo commit.
Eliminar un fichero
En el diagrama siguiente podemos ver el histórico de commits. Los trees y blobs del último commit, así como la working copy y el index:
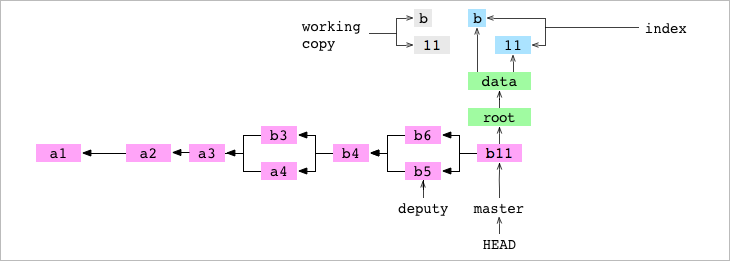
El usuario le dice a Git que elimine data/letter.txt. El archivo se elimina de la WORKING COPY y del Index.
➜ alpha git:(master) > git rm data/letter.txt
rm 'data/letter.txt'
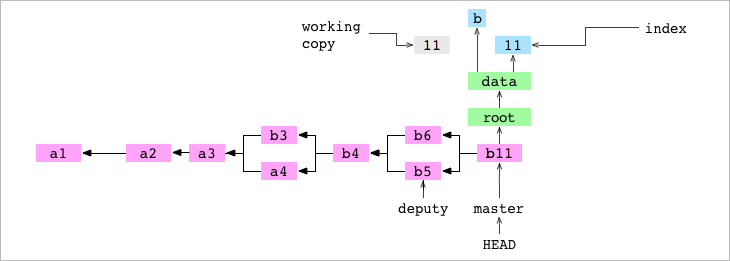
Hacemos un commit. Como parte del mismo, como siempre, GIT construye un tree que representa el contenido del Index. El archivo data/letter.txt no se incluye en el tree graph porque no está en el Index.
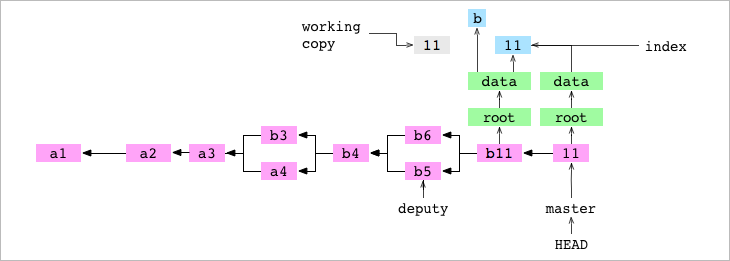
➜ alpha git:(master) ✗ > git commit -m '11'
[master cb09056] 11
1 file changed, 1 deletion(-)
delete mode 100644 data/letter.txt
Copiar un repositorio
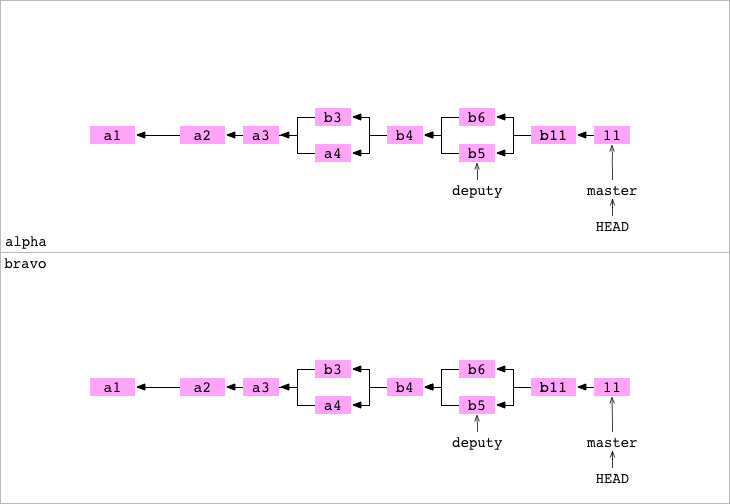
Vamos a cambiar de tercio. Ahora vamos a copiar el contenido del repositorio alpha/ a un nuevo directorio bravo/ directory. Esto provoca la siguiente estructura:
➜ alpha git:(master) > cd ..
➜ ~ > cp -R alpha bravo
.
├── alpha
│ └── data
│ └── number.txt
└── bravo
└── data
└── number.txt
Tenemos otro GIT graph en el directorio bravo:
Enlazar un repositorio con otro
Nos volvemos al repositorio alpha y configuramos como repositorio remoto a bravo.
➜ > cd alpha
➜ alpha git:(master) > git remote add bravo ../bravo
Esto va a suponer que se añaden algunas líneas al fichero alpha/.git/config:
[remote "bravo"]
url = ../bravo
fetch = +refs/heads/*:refs/remotes/bravo/*
Estas líneas especifican que hay un repositorio remote llamado bravo en el directorio ../bravo.
Fetch desde un remoto
En concreto vamos a hacer un Fetch de una branch desde un remote.
Pero antes vamos a cambiar el contenido de data/number.txt a 12 en el repositorio bravo junto con su commit (que nombro como 12).
➜ alpha git:(master) > cd ../bravo
➜ bravo git:(master) > echo '12' > data/number.txt
➜ bravo git:(master) ✗ > git add data/number.txt
➜ bravo git:(master) ✗ > git commit -m '12'
[master b3f3fca] 12
1 file changed, 1 insertion(+), 1 deletion(-)
➜ bravo git:(master) >
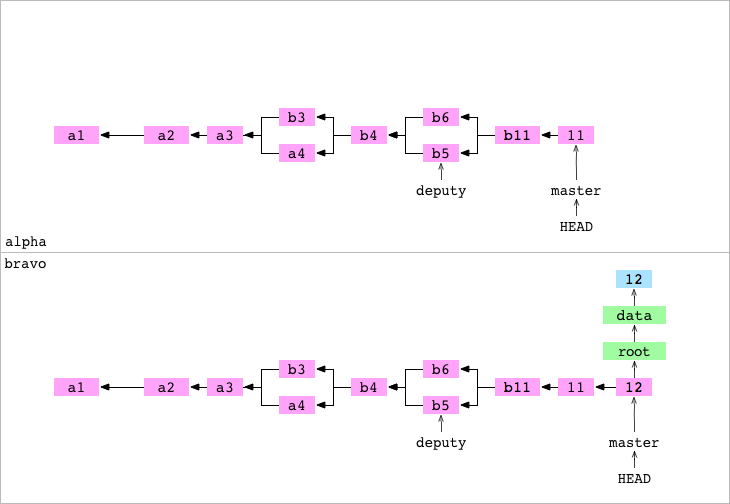
Ahora hacemos el Fetch desde el remoto. Entra en el repositorio alpha y se trae (fetch) el master desde el repositorio remoto bravo, un proceso que consta de cuatro pasos.
➜ alpha git:(master) > git fetch bravo master
remote: Enumerating objects: 7, done.
remote: Counting objects: 100% (7/7), done.
remote: Total 4 (delta 0), reused 0 (delta 0)
Unpacking objects: 100% (4/4), done.
From ../bravo
* branch master -> FETCH_HEAD
* [new branch] master -> bravo/master
- Paso #1: Git obtiene el hash del commit
12al que está apuntandomasterenbravo. - Paso #2: Git hace una lista de todos los objetos de los que depende el commit
12, el objeto commit en si mismo, los objetos del tree graph, los ancestros a dicho commit y los objetos en sus tree graphs. Elimina de su lista cualquier objeto quealphaya tuviese por si mismo y copia el resto de objetos a.git/objects/. - Paso #3: El contenido del archivo de referencia concreto en
alpha/.git/refs/remotes/bravo/masterse ajusta al hash del commit12. - Paso #4: El contenido de
alpha/.git/FETCH_HEADse se establece en:
➜ alpha git:(master) > cat .git/FETCH_HEAD
b3f3fca9a5f40c6ff21dddec1657d5d0c435ec61 branch 'master' of ../bravo
FETCH_HEAD es una referencia (de corta duración) que nos indica lo que se acaba de obtener desde un repositorio remoto. Más técnicamente FETCH_HEAD apunta a la punta de esa branch remota (almacenando el SHA1 del commit, tal como hacen las branchs). git pull entonces invoca a git merge, fusionando FETCH_HEAD en la branch actual. Al ver su contenido observamos que el comando fetch más reciente viene del commit 12 de la branch master del repositorio bravo.
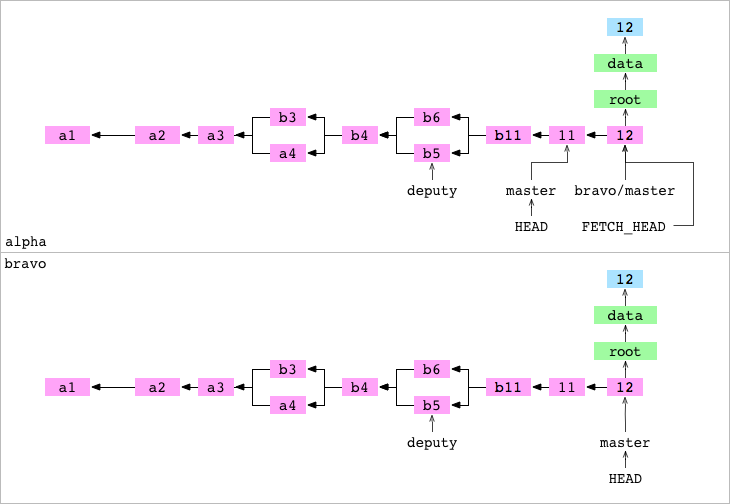
-
Los objetos se pueden copiar, significa que la historia se puede compartir entre repositorios.
-
Un repositorio puede almacenar referencias de branchs remotas como
git/refs/remotes/bravo/master. Esto significa que un repositorio puede registrar localmente el estado de una branch en un repositorio remoto. Es correcto en el momento en que se obtiene, pero se desactualiza si la branch remota cambia.
Merge FETCH_HEAD
Dijimos antes que FETCH_HEAD es una referencia (de corta duración) que nos indica lo que se acaba de obtener desde un repositorio remoto.
Cuando fusionamos FETCH_HEAD resolverá siendo el emisor/dador el commit 12 y el receptor el HEADcon el commit 11. Git hace un merge rápido y apunta master al commit 12.
➜ alpha git:(master) > git merge FETCH_HEAD
Updating cb09056..b3f3fca
Fast-forward
data/number.txt | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
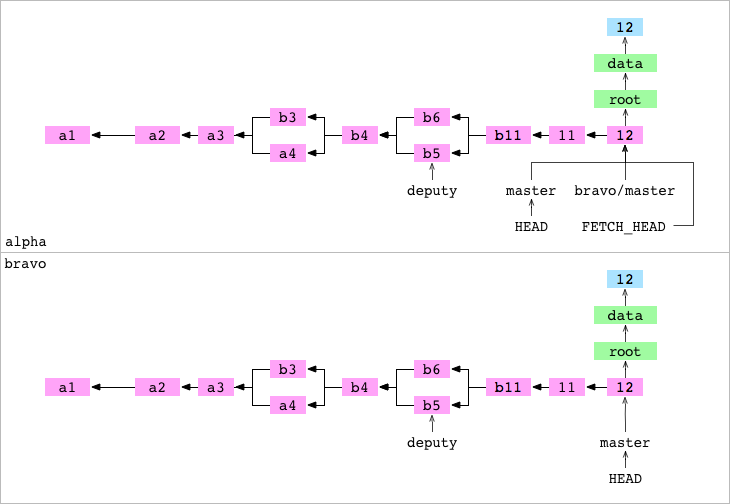
Pull de una branch remota
Pull es la abreviación de fetch & merge the FETCH_HEAD (fetch y después merge del FETCH_HEAD). Es decir, hacemos un pull(“tiramos”) de una branch desde un repositorio remoto.
En el siguiente ejemplo hacemos el pull de master desde el repositorio bravo. El comando git hace el fetch+merge pero nos informa que master ya estaba actualizado porque en los pasos anteriores ya habíamos hecho el fetch y el merge por separado.
➜ alpha git:(master) > git pull bravo master
From ../bravo
* branch master -> FETCH_HEAD
Already up to date.
Clone de un repositorio
Clone viene de “clonar”, consiste en obtener una copia de un repositorio existente.
Con git clone recibirás una copia de casi todos los datos que están en el repositorio remoto (aquí estamos jugando con directorios locales, pero lo normal es que sea un servidor remoto como GitHub o GitLab). Al clonar se descargará cada versión de cada archivo de la historia del proyecto.
Veamos como clonamos alpha, hacia un nuevo directorio llamado charlie. En este caso alpha es el repositorio que existe y lo estamos duplicando y llamándolo charlie
➜ rep > git clone alpha charlie
Cloning into 'charlie'...
done.
La clonación tiene resultados similares a los de que el usuario hizo para producir el repositorio bravo. Git crea un nuevo directorio llamado charlie. Lo inicializa y añade a alpha como un remote al que llama origin y lanza fetch desde origin pidiendo que se haga un merge de FETCH_HEAD.
Si observamos el repositorio de charlie vemos que tiene configurado un remote hacia el repositorio alpha:
➜ rep > cat charlie/.git/config
:
[remote "origin"]
url = /Users/luis/rep/alpha
fetch = +refs/heads/*:refs/remotes/origin/*
:
➜ rep > tree -a charlie
charlie
├── .git
: :
│ └── refs
: :
│ ├── remotes
│ │ └── origin
│ │ └── HEAD
➜ rep > cat charlie/.git/refs/remotes/origin/HEAD
ref: refs/remotes/origin/master
Push desde respositorio previamente clonado
Veamos un caso curioso para entender mejor porqué son importantes los respositorios vacíos, bare repository que veremos en la siguiente sección. Volvemos sobre nuestros pasos, tenemos el respositorio charlie que había clonado a alpha. Vamos a intentar modificar el origen (alpha) y desde él vamos a intentar enviarle las modificaciones (push) a charlie (cambios en su .git sin su permiso 😂).
Para que alpha pueda hacer un push hacia charlie primero lo tendrá que añadir como remote. Claro que es posible, de hecho en GIT puedes/debes tener configurados los repositorios como remotes entre ellos para solicitar o enviar cambios. Al lio, repetimos: charlie clonó a alpha, alguien modifica este último y quiere enviarle las modificaciones con un push hacia charlie, git lo para y se queja !!
Empezamos entrando en alpha. Modificamos data/number.txt con un 13 y hacemos commit en master.
➜ > cd alpha
➜ alpha git:(master) > echo '13' > data/number.txt
➜ alpha git:(master) ✗ > git add data/number.txt
➜ alpha git:(master) ✗ > git commit -m '13'
[master 102bd7d] 13
1 file changed, 1 insertion(+), 1 deletion(-)
Añado a charlie como un repositorio remoto de alpha.
➜ alpha git:(master) > git remote add charlie ../charlie
Intentamos un Push de master hacia charlie. Todos los objetos requeridos para el commit 13 se mandan, pero al intentar actualizar la branch remota gitse queja y para.
➜ alpha git:(master) > git push charlie master
Enumerating objects: 7, done.
Counting objects: 100% (7/7), done.
Writing objects: 100% (4/4), 289 bytes | 289.00 KiB/s, done.
Total 4 (delta 0), reused 0 (delta 0)
remote: error: refusing to update checked out branch: refs/heads/master
remote: error: By default, updating the current branch in a non-bare repository
remote: is denied, because it will make the index and work tree inconsistent
remote: with what you pushed, and will require 'git reset --hard' to match
remote: the work tree to HEAD.
¿qué ha pasado?. Git, como siempre, le dice al usuario lo que salió mal. Se niega a hacer push sobre la branch remote (charlie/master) porque tocaría el Index remoto y el HEAD remoto y le causaría confusión si alguien estuviera editando la working copy de dicho remote
Una opción para colaborar entre repositorios remotos interconectados entre ellos sería crear branches nuevas cada dos por tres y hacerles push entre ellos, pero sería inmanejable, demasiada confusión. Otra cosa a pensar es si queremos repositorios a los que se pueda hacer push en cualquier momento.
En realidad lo que queremos es un repositorio central al que se pueda hacer push y pull, pero que no acepte commits directamente, un intermediario. Eso tiene un nombre, se conoce como un bare repository (repositorio vacío).
Clonar un Bare Repository
Un Bare Repository es un repositorio vacío. Nos cambiamos al directorio anterior. Clono delta como un repositorio vacío (bare).
➜ alpha git:(master) > cd ..
➜ rep > git clone alpha delta --bare
Cloning into bare repository 'delta'...
done.
En realidad es un clonado ordinario pero con dos diferencias: El fichero config nos dice que es un bare y los ficheros que normalmente se guardarían bajo .git se guardan en la raíz del repositorio:
delta
├── HEAD
├── config
├── description
├── hooks
├── info
├── objects
├── packed-refs
└── refs
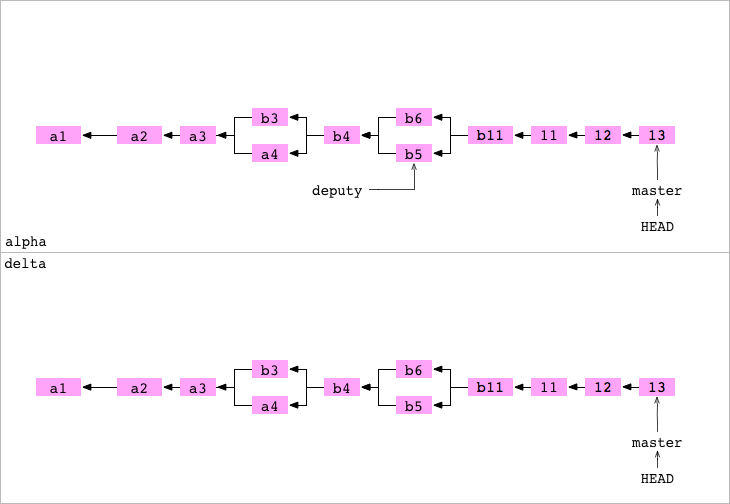
Push hacia un bare repository
Vamos a hacer un Push de una branch hacia un repositorio vacío bare repository.
Vamos a repetir lo que antes nos fallo. Volvemos al repositorio alpha. Configuro a delta (repositorio vacío) como un repositorio remoto de alfa.
➜ > cd alpha
➜ alpha git:(master) > git remote add delta ../delta
Modifico alpha, cambio el contenido de data/number.txt a un 14 y realizo un commit en masteren alpha.
➜ alpha git:(master) > git remote add delta ../delta
➜ alpha git:(master) > echo '14' > data/number.txt
➜ alpha git:(master) ✗ > git add data/number.txt
➜ alpha git:(master) ✗ > git commit -m '14'
[master af337b6] 14
1 file changed, 1 insertion(+), 1 deletion(-)
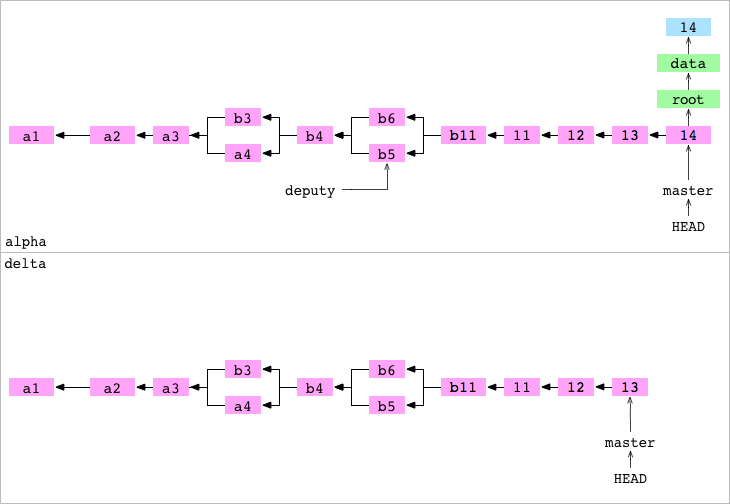
➜ alpha git:(master) > git push delta master
Enumerating objects: 7, done.
Counting objects: 100% (7/7), done.
Writing objects: 100% (4/4), 291 bytes | 291.00 KiB/s, done.
Total 4 (delta 0), reused 0 (delta 0)
To ../delta
102bd7d..af337b6 master -> master
➜ alpha git:(master) >
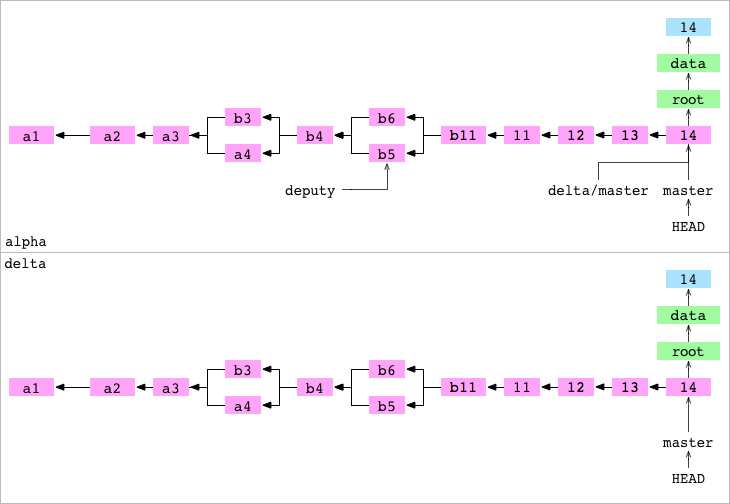
Push de master hacia el repositorio Bare delta. El push tiene tres pasos:
- Paso #1: Se copian todos los objetos necesarios para el commit
14en la branchmasteren.git/objects/haciadelta/objects/. - Paso #2: Se actualiza
delta/refs/heads/masterpara apuntar al commit14. - Paso #3: Se establece
alpha/.git/refs/remotes/delta/masterse establece para que apunte al commit14Elalphatiene un registro actualizado del estado dedelta.
Ejemplos de uso con repositorios reales
Muestro a continuación algunos comandos típicos
- Mi clone local apunta a un
remotevía HTTP y quiero cambiarlo aSSH
Comando: git remote set-url origin git@github.com:LuisPalacios/Master-DS.git
luis@coder:~/notebooks/Master-DS$ cat .git/config
:
[remote "origin"]
url = https://github.com/LuisPalacios/Master-DS.git
:
luis@coder:~/notebooks/Master-DS$ git remote set-url origin git@github.com:LuisPalacios/Master-DS.git
luis@coder:~/notebooks/Master-DS$ cat .git/config
:
[remote "origin"]
url = git@github.com:LuisPalacios/Master-DS.git
:
Resumen
GIT se estructura alrededor de un árbol gráfico y casi todos sus comandos lo manipulan. Para entenderlo en profundidad céntrate en las propiedades de dicho gráfico, no en los flujos de trabajo o los comandos.
Para aprender más sobre Git, investiga el directorio .git, que no te asuste, mira dentro, cambia el contenido de los archivos a ver qué pasa. Crea un commit, intenta estropear el repositorio para luego arregarlo.
-
En este caso, el hash es más largo que el contenido original, pero este método unifica la forma en la que GIT va a nombrar los archivos, de manera mucho más concisa que usando sus nombres originales. ↩
-
Existe la posibilidad de que dos piezas de contenido diferentes tengan el mismo valor, pero la probabilidad de que ocurra es realmente insignificante ↩
-
El comando
git prunepermite borrar objetos huérfanos (aquellos que están siendo apuntados por ninguna referencia). Solo debe usarse para tareas de mantenimiento. Si usas este comando sin saber lo que estás haciendo podrías llegar a perder contenido. ↩ -
El comando
git stashalmacena todas las diferencias entre la copia de trabajo y el commitHEADen un lugar seguro. Puede ser recuperado más tarde congit stash pop. ↩ -
El comando
git rebasepuede utilizarse para añadir, editar y borrar commits en el historial. Nos puede ayudar a evitar conflictos, aunque hay que entender bien cómo funciona y mejor aplicarlo sobre sobre commits que están en local y no han sido subidos a ningún repositorio remoto ↩